Een best wel ingewikkeld onderwerp in één tool: RiC-E.
De essentie van mijn vorige blogpost bleef nog lange tijd door mijn hoofd spoken en wel hierom: zo'n 20 jaar geleden, tijdens de hype rond de introductie van EAD (Encoded Archival Description)Zie: https://loc.gov/ead. in Nederland, was ik betrokken bij de ontwikkeling van een EAD export module voor ABS-Archeion, een logistiek beheersysteem voor archieven, én een EAD Editor: proMEAD (project Making EAD). Vooral van proMEAD had ik hoge verwachtingen. Die EAD Editor was bedoeld om op een gebruiksvriendelijke manier - via invulformulieren - een archiefinventaris (toegang) te maken volgens de ISAD(G) standaardZie: https://www.ica.org/resource/isadg-general-international-standard-archival-description-second-edition., waarna eenvoudig met één druk op een knop een EAD/XML versie van die toegang kon worden gegenereerd, klaar om te importeren in een op EAD/XML gebaseerd zoeksysteem. Het idee daarachter voelde toen behoorlijk vernieuwend: niet langer EAD/XML "met de hand" produceren, maar archivarissen laten werken in een omgeving die aansloot op hun dagelijkse praktijk, terwijl de technische complexiteit van de omzetting naar EAD/XML zoveel mogelijk 'onder de motorkap' werd afgehandeld.
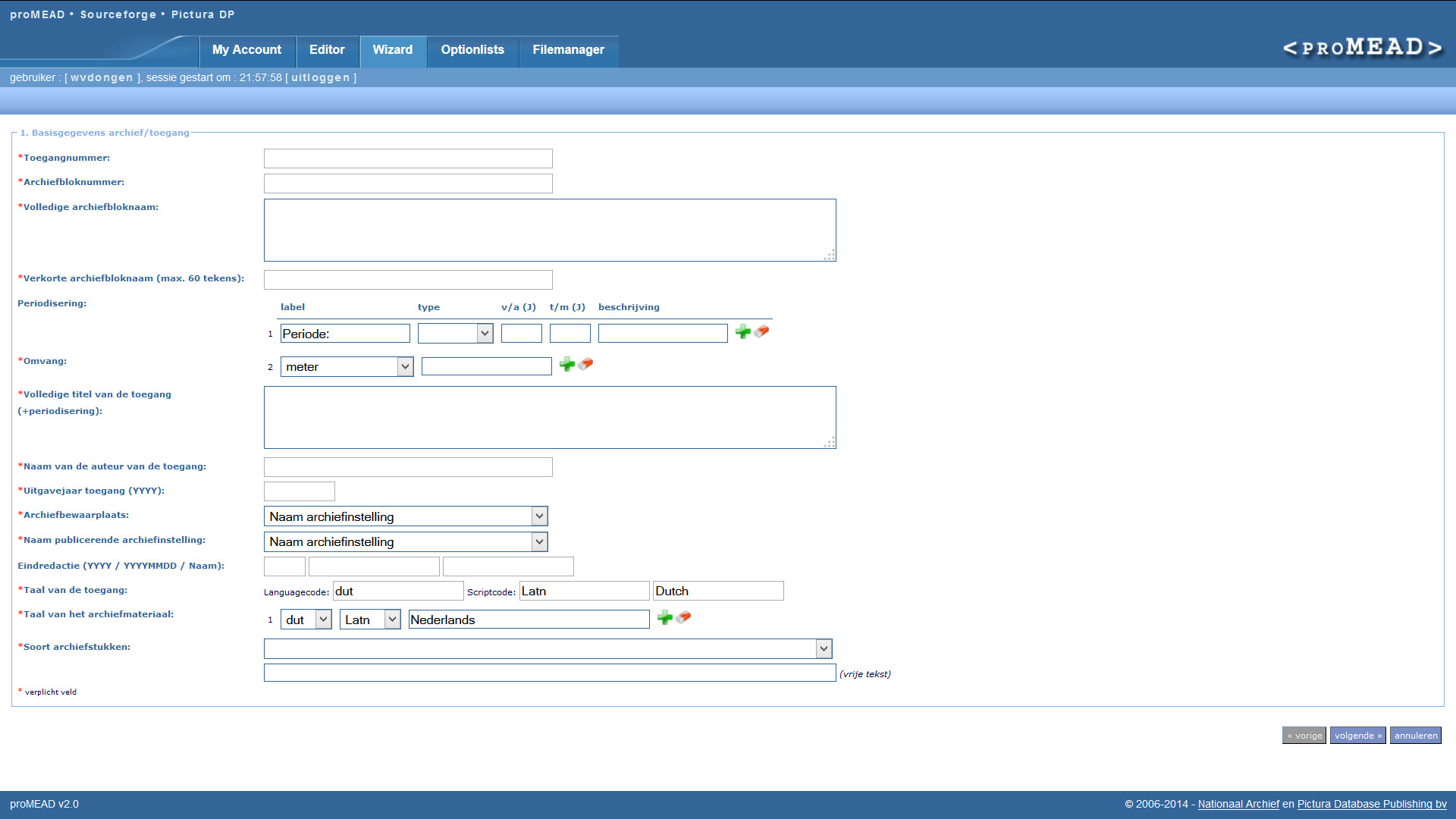
Van EAD Editor naar RiC Editor
Helaas was proMEAD geen lang leven beschoren. Na de lancering ervan kwamen er toch nog wat bugs boven water die opgelost moesten worden, maar de aandacht binnen het Nationaal Archief - mijn toenmalige werkgever en opdrachtgever voor het project - verschoof volledig naar de ontwikkeling van de nieuwe website, GaHetNa, waardoor de financiering voor alle andere projecten geheel opdroogde, en ikzelf raakte ondertussen steeds intensiever betrokken bij het internationale Archieven Portaal Europa (APE) projectZie: https://www.archivesportaleurope.net, en ook: http://apenet.eu en: http://www.apex-project.eu.. Op een gegeven moment lukte het nog wel om een APE-ontwikkelaar enthousiast te krijgen om de meeste proMEAD bugs op te lossen, wat uiteindelijk resulteerde in een proMEAD 2.0 versie, maar tegen de tijd dat er weer ruimte ontstond om deze versie te lanceren, werd het PHP framework waarbinnen proMEAD draaide (Seagull) niet meer ondersteund, evenals de onderliggende PHP- en MySQL-versies. Kortom: de proMEAD 2.0 code belandde uiteindelijk ergens op een van mijn archief harde schijven en daar bleef het bij.
Tot voor kort: want plotseling - na mijn pensionering - onstond er weer iets wat vroeger vooral ontbrak: tijd. Aanvankelijk dacht ik na over een herstart van proMEAD, dus een versie 3.0, maar al gauw bleek dat dit - door het verouderde framework - meer een 'retrocomputing' project zou worden en bovendien was ondertussen in de archiefwereld de tijd niet stil blijven staan: EAD voelt inmiddels vertrouwd en is volledig ingeburgerd, terwijl een nieuwe archiefstandaard, Records in Contexts (RiC)Zie: https://www.ica.org/ica-network/expert-groups/egad/records-in-contexts-ric., is verschenen en allerlei fundamentele vragen begint op te roepen over archiefbeschrijvingen, relaties en context(s). Dus ontstond langzamerhand een ander idee: misschien is het geen tijd meer voor een EAD Editor, maar tijd voor een RiC Editor, oftewel: RiC-E ;-).
De afgelopen 20 jaar is niet alleen in de archiefwereld de tijd niet stil blijven staan, ook in de technische wereld is er veel vooruitgang geboekt en mijn eigen kennis en ervaring zijn daarin meegegroeid. Door mijn betrokkenheid bij de open source e-depot applicatie ArchivematicaZie: https://www.archivematica.org/en. ben ik behoorlijk gecharmeerd geraakt van DjangoZie: https://www.djangoproject.com.. Dit framework is robuust, relatief overzichtelijk en vooral geschikt om snel een werkende applicatie op te zetten. Daar heb ik inmiddels wat ervaring mee, dus besloot ik een poging te wagen om een RiC Editor in Django te bouwen, met twee bescheiden doelstellingen voor ogen. De eerste is praktisch: onderzoeken of het mogelijk is om een gebruiksvriendelijke editor te maken voor een relationeel archiefbeschrijvingsmodel (met mijn ervaring met Omeka-S in het achterhoofdZie: https://cannedit.org/blog/omeka-s-en-de-wondere-wereld-van-linked-data.). De tweede is eerlijk gezegd voor mijzelf de meest belangrijke: RiC en de (on)mogelijkheden daarvan beter begrijpen door het daadwerkelijk proberen te implementeren.
Dat laatste deed ik 20 jaar geleden ook. Destijds leerde ik EAD pas echt goed doorgronden tijdens het begeleiden van de ontwikkeling van de ABS-Archeion exportmodule en proMEAD. Pas wanneer je software probeert te bouwen rond een standaard ontdek je waar de onduidelijkheden zitten, kom je impliciete aannames tegen en zie je welke onderdelen theoretisch elegant zijn, maar praktisch lastig toepasbaar blijken. Bij de implementatie van RiC blijkt dat niet anders.
De basis
Vanaf het begin had ik een paar uitgangspunten voor ogen. De belangrijkste was misschien wel: probeer toekomstige gebruikers niet rechtstreeks met de complexiteit van RiC te confronteren. Dat klinkt misschien vanzelfsprekend, maar RiC kan behoorlijk intimiderend worden zodra termen als ontologieën, triples, RDF of semantische relaties ter sprake komen. Een archivaris denkt in de praktijk helemaal niet in triples. Die denkt eerder in vragen als: wie heeft dit document gemaakt, uit welke activiteit komt het voort, met welke personen, organisaties, activiteiten of plaatsen en onderwerpen hangt het samen? Daarom heb ik - weer - geprobeerd het werken in de RiC Editor zoveel mogelijk via invulformulieren te laten verlopen, terwijl ingewikkeldere zaken zoveel mogelijk 'onder de motorkap' worden afgehandeld.
Verder besloot ik om niet meteen alle elementen van RiC te ondersteunen maar alleen de meest basale, een soort RiC-light dus, en ook niet alle 'entiteiten' een prominente plaats te geven in het 'dashboard' van de RiC Editor. Of dat allemaal goed gelukt is zonder afbreuk te doen aan RiC weet ik eerlijk gezegd niet, maar het voelde wel als de enige manier om relationeel werken enigszins toegankelijk en overzichtelijk te houden.
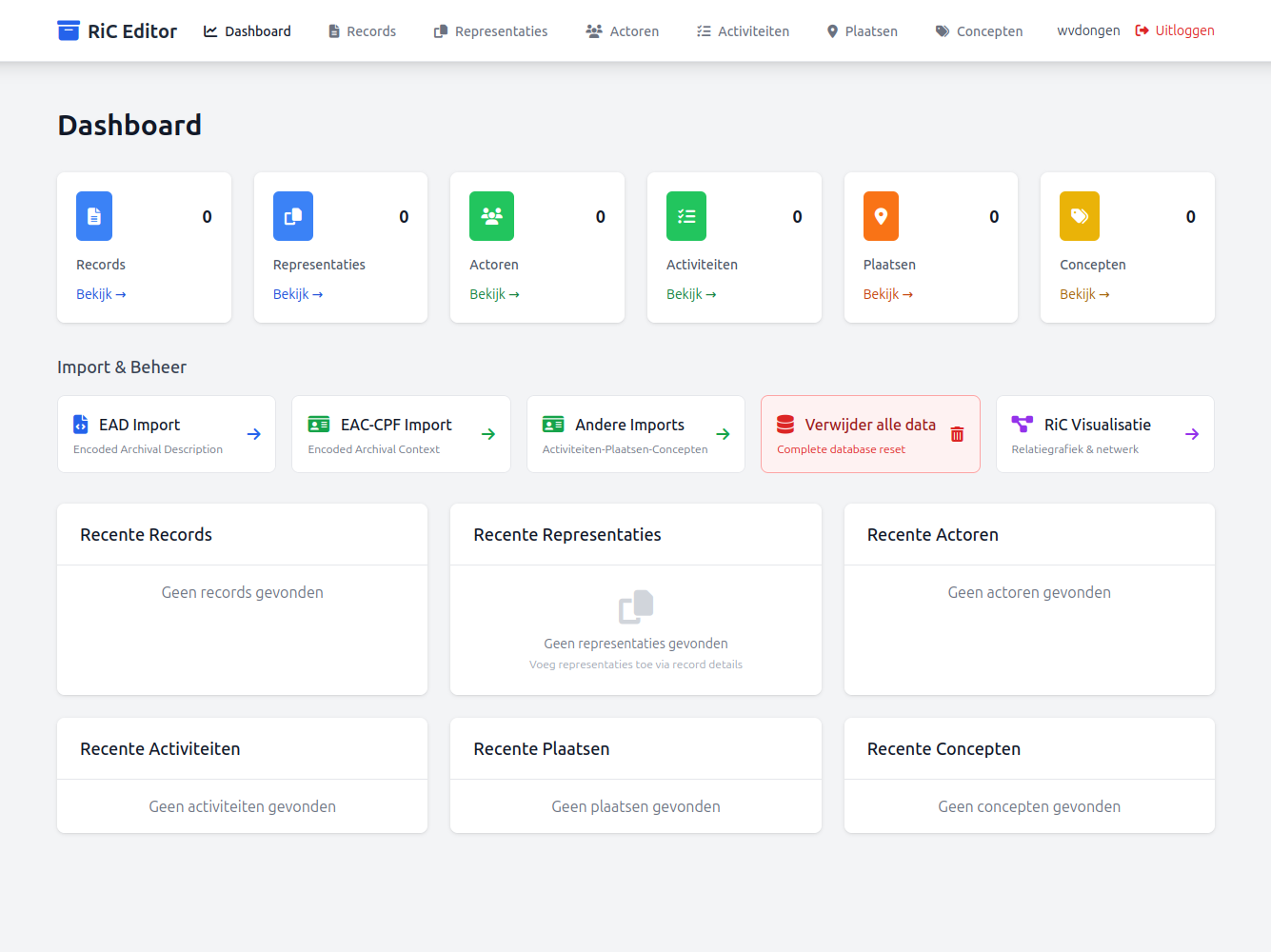
Als basis biedt de RiC Editor de mogelijkheid alle belangrijke RiC entiteiten handmatig in te vullen via de menu opties van het dashboard, maar vrij snel werd duidelijk dat een RiC Editor zonder import mogelijkheden eigenlijk weinig zin heeft. Hoewel de RiC Editor niet bedoeld is als een soort collectie management systeem, maar puur als een 'sandbox' voor degenen die willen experimenteren met het beschrijven van archieven volgens de RiC standaardHet 'sandbox' karakter van de RiC Editor wordt met name duidelijk via de rode knop: "Verwijder alle data" in het dashboard. Via die optie kan de hele onderliggende database eenvoudig leeg worden gemaakt en kan een gebruiker 'met een schone lei' opnieuw beginnen. , gaat natuurlijk niemand vele al bestaande beschrijvingen van archiefmateriaal of archiefvormers met de hand opnieuw invoeren. Daarom kreeg ondersteuning voor de import van bestaande XML bestanden in de gangbare EAD- en EAC-CPF-versiesEAD2002 (inclusief apeEAD) en EAD3; EAC-CPF 2010 (inclusief apeEAC-CPF) en EAC-CPF 2.0 (2022). Zie: https://loc.gov/ead, https://eac.staatsbibliothek-berlin.de/ en: https://www.archivesportaleurope.net/tools/for-content-providers/standards/. al vroeg prioriteit.
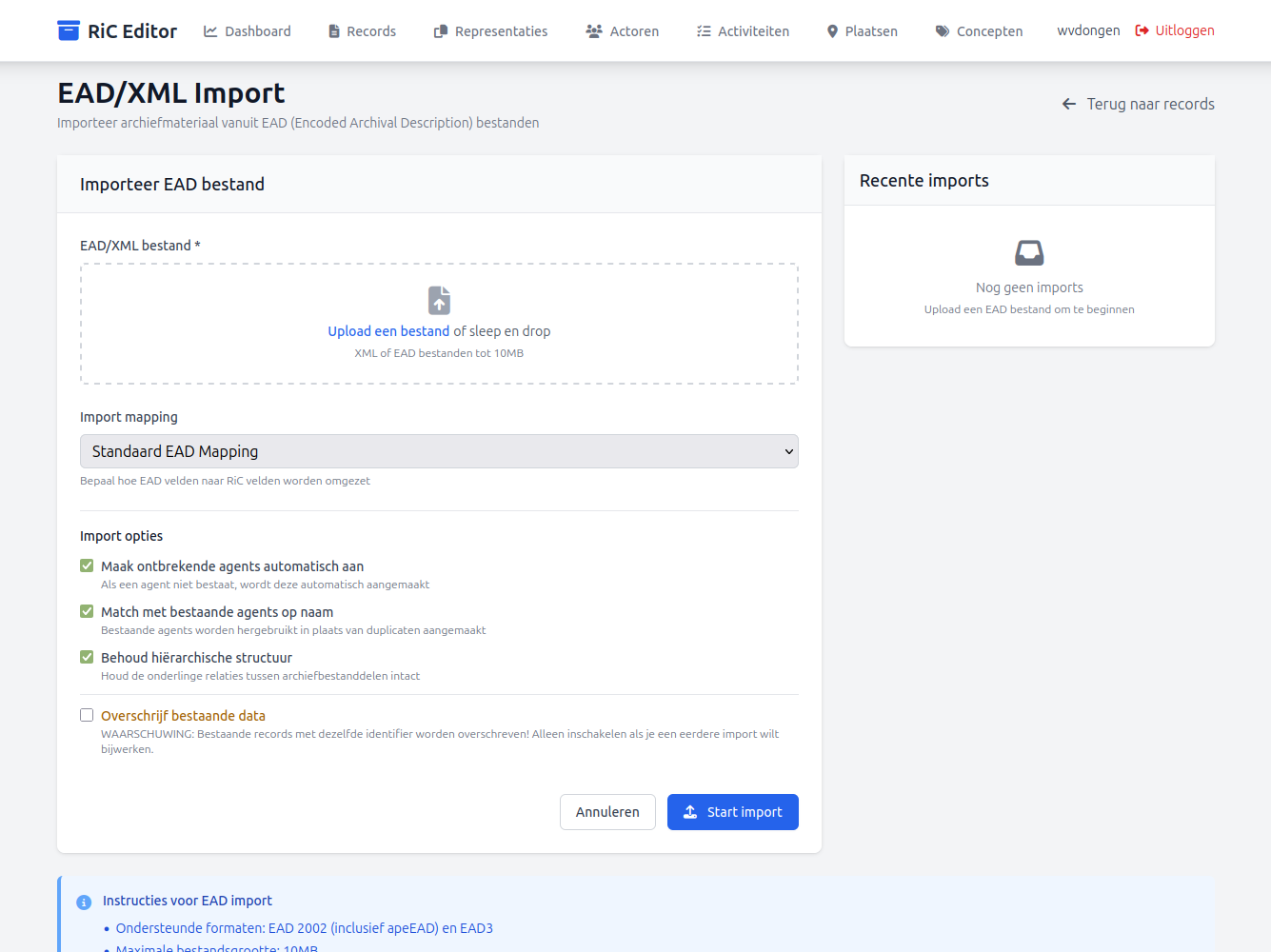
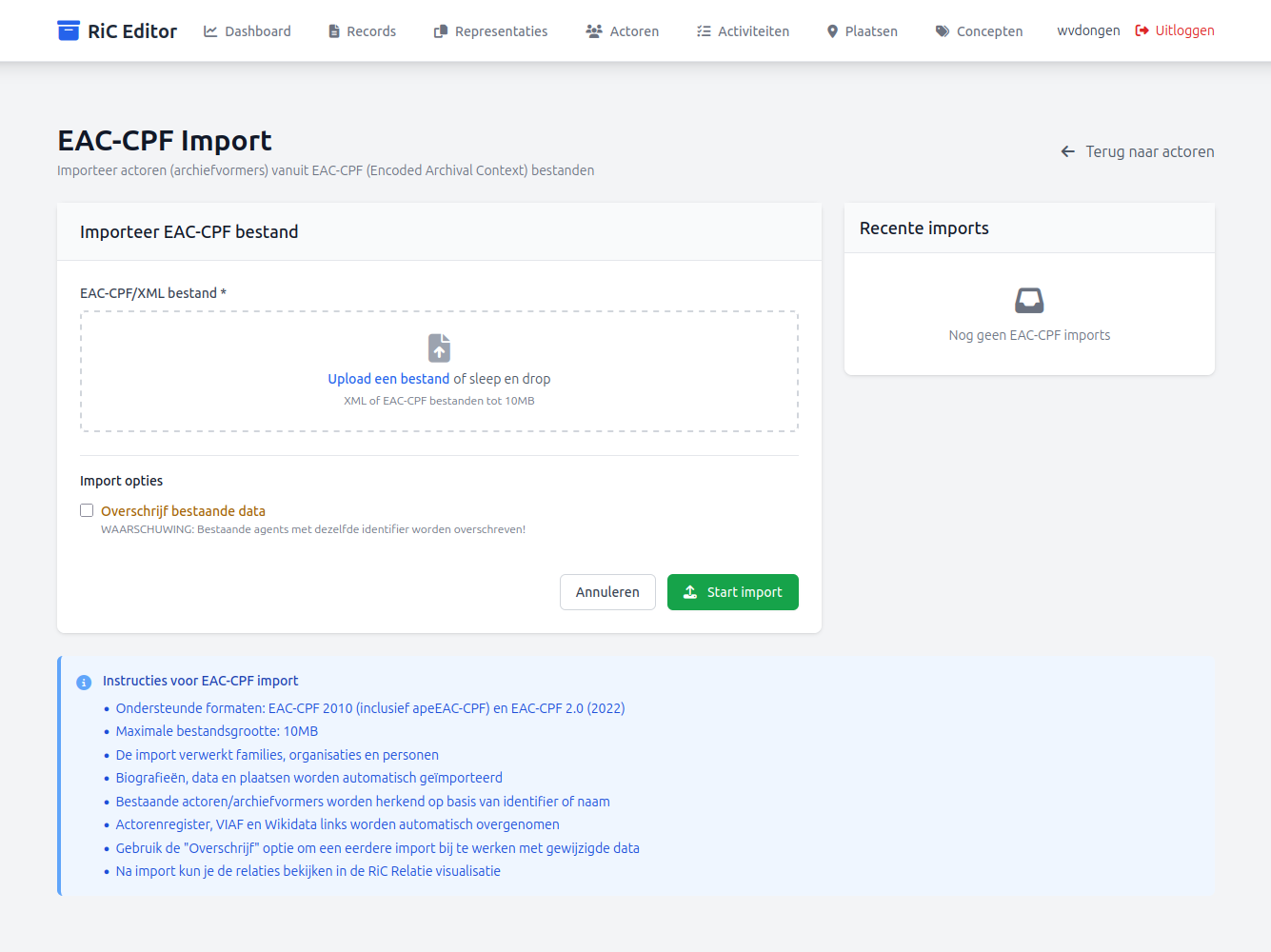
Tijdens de import van EAD en EAC-CPF XML bestanden controleert de RiC Editor of deze informatie bevatten die kunnen worden verwerkt in andere RiC entiteiten, zoals de onder 'Concepten' ondergebrachte 'Functies', 'Mandaten' en 'Onderwerpen', en als dat het geval is worden de betreffende velden automatisch gevuld en worden er relaties gelegd tussen die Concepten en de Records en Actoren die uit de EAD en EAC-CPF XML bestanden zijn opgehaald en vastgelegd. Uiteraard worden ook relaties tussen Records en Actoren in de EAD en EAC-CPF XML bestanden opgespoord en geregistreerd. Al deze informatie kan via de detail pagina's van alle RiC entiteiten worden bekeken, gewijzigd en aangevuld en ontbrekende relaties tussen die RiC entiteiten kunnen handmatig alsnog worden aangebracht.
In de praktijk blijkt dat in bestaande EAD en EAC-CPF XML bestanden weinig informatie over Functies, Mandaten en Onderwerpen is vastgelegd (en ook niet over Activiteiten en Plaatsen) en dat soort informatie is nu juist heel belangrijk voor RiC, vooral in de vorm van consistente terminologie, controlled vocabularies en authority files. Daarom wilde ik de RiC Editor ook eenvoudig dat soort informatie laten importeren. Maar daar begint meteen een probleem: welke controlled vocabularies of thesauri gebruik je dan eigenlijk? Voor Plaatsen en Onderwerpen is dat inmiddels niet meer zo'n probleem, maar voor Activiteiten, Functies en Mandaten wel. Veel bestaande thesauri blijken sterk afhankelijk van lokale situaties waarbinnen archiefinstellingen opereren. Ook beschikken sommige instellingen over uitgebreide thesauri en hebben andere er nagenoeg geen. Juist daarom heb ik uiteindelijk gekozen voor een relatief open import functie waarbij gebruikers hun eigen thesauri kunnen importeren als CSV bestanden, aangevuld met voorbeeld bestandenTijdens de ontwikkeling van deze functie moest ik regelmatig denken aan het PIVOT project en de daaruit voortgekomen Institutionele Toegangen en Handelingenbank. Eigenlijk was dit project zijn tijd verrassend ver vooruit. In zekere zin werd daarin geprobeerd iets vast te leggen wat sterk lijkt op relationele context modellering: niet alleen beschrijven welke documenten er zijn, maar vooral waarom die documenten bestaan en uit welke handelingen ze voortkwamen..
Eén van de interessantste onderdelen om aan te werken vond ik uiteindelijk de relaties zelf. In theorie is het idee van RiC prachtig: Records, Actoren, Activiteiten, Plaatsen en Concepten vormen samen een netwerk van betekenisvolle verbanden. Maar zodra je dat daadwerkelijk probeert te implementeren ontstaat vrijwel onmiddellijk een probleem: relationele overvloed. Want als vrijwel alles met vrijwel alles verbonden kan worden, hoe houd je dat dan nog overzichtelijk?
Daarom ben ik begonnen met een eenvoudige "relatie visualisatie" in de RiC Editor. Maar ik wilde daarvoor beslist geen zware, complexe Graph-database of Linked-Data infrastructuur optuigen, want een van mijn uitgangspunten was ook dat de RiC Editor een doodgewone applicatie moet zijn, die iedereen op een normale laptop kan draaien, of eventueel zelfs kan worden aangeboden binnen een eenvoudige shared webhosting omgeving. Dat is uiteindelijk gelukt, inclusief het via die visualisatie kunnen ophalen van de volledige beschrijving van RiC entiteiten via hun detail pagina's, plus mijn eerste pogingen tot export van het getoonde naar JSON-LD en RDF Turtle. Het is misschien niet spectaculair, maar wel praktisch. Want juist daar zit volgens mij een belangrijke uitdaging voor RiC: niet alleen relaties kunnen opslaan, maar ze ook zichtbaar, begrijpelijk en beheersbaar maken.
Een sneak preview
Hieronder een screenshot van het Records overzicht in de RiC Editor nadat een zeer eenvoudig EAD/XML document is ingelezen, dat van Nationaal Archief toegang 2.13.80 (Inventaris van het archief van de Commissie voor het model van de veldjas, 1937-1940), een kleine basis toegang die ik 20 jaar geleden ook al als test toegang gebruikte bij EAD experimentenDit is echter niet de EAD/XML versie van toegang 2.13.80 die momenteel online staat op de website van het Nationaal Archief, maar de oude van ca. 20 jaar geleden, want blijkbaar is deze toegang later bij het Nationaal Archief ook nog door anderen als test toegang gebruikt, zonder de test elementen daarna te verwijderen, Zie: https://nationaalarchief.nl/onderzoeken/archief/2.13.80..
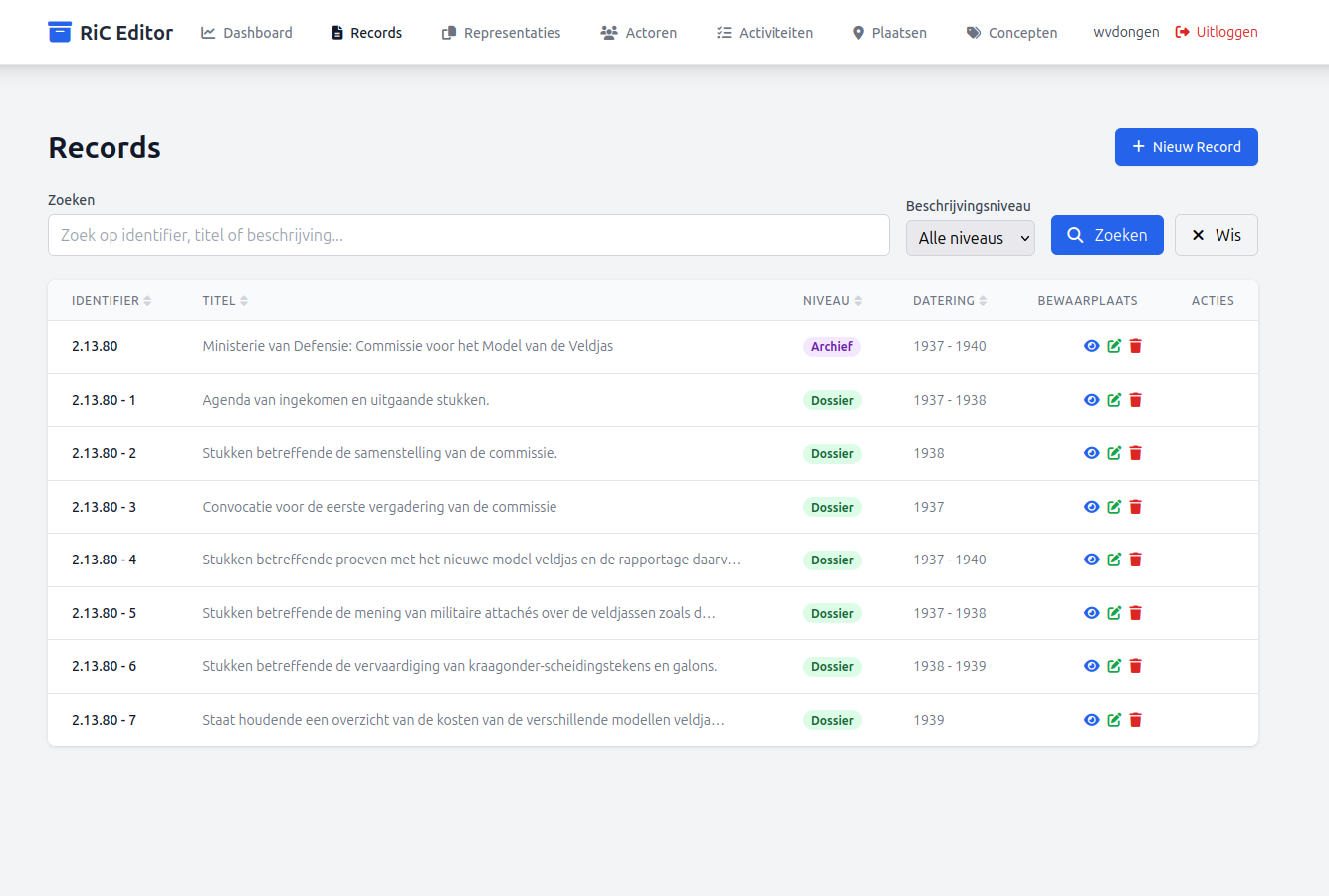
Het screenshot hieronder laat zien dat na de import van toegang 2.13.80 de RiC Editor de daarin opgenomen archiefvormer "Commissie voor het model van de veldjas" netjes als Actor heeft geregistreerd, met als enige relaties die met de bijbehorende Records.
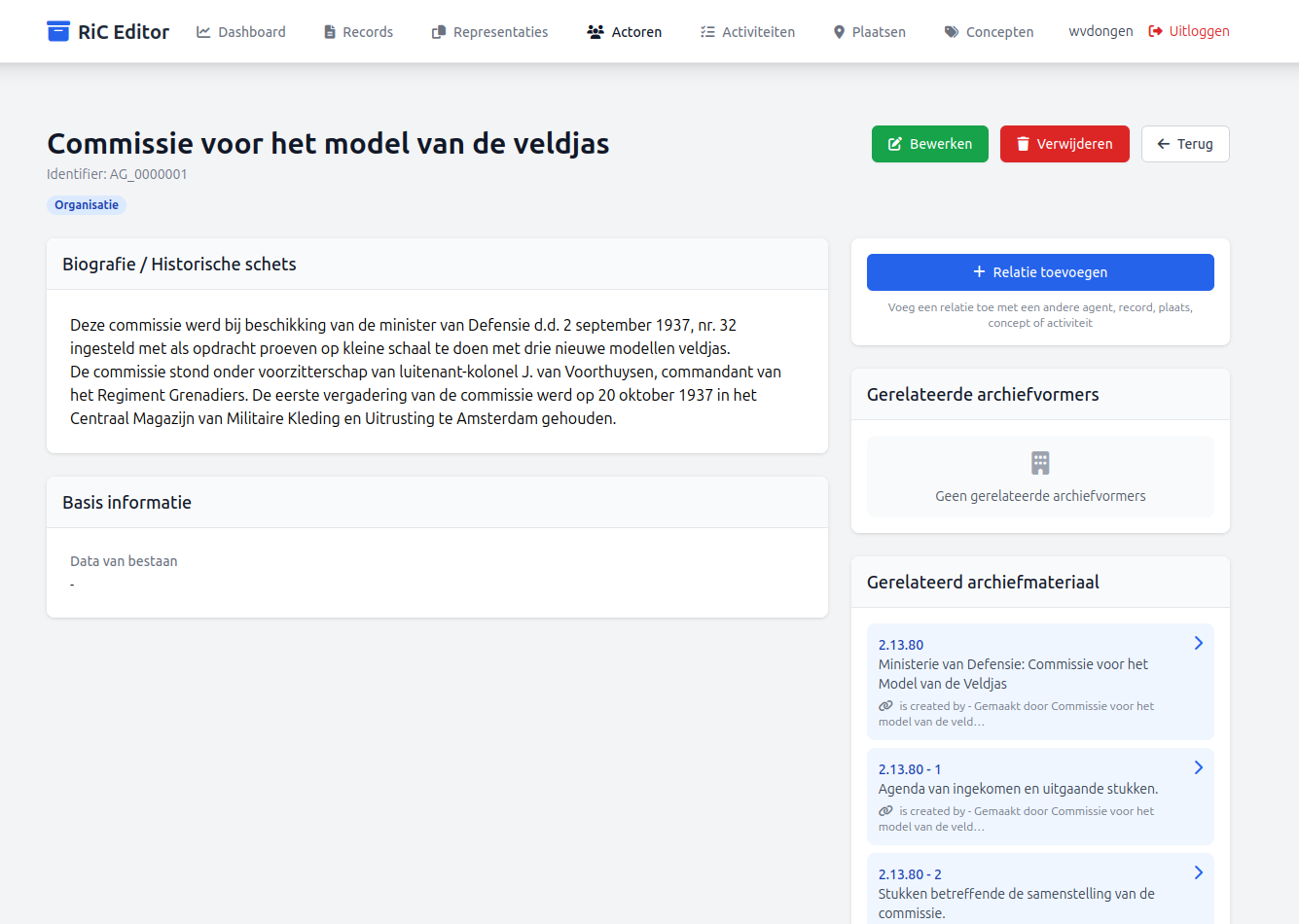
In het door het Nationaal Archief ingerichte Actorenregister komen we de Actor "Commissie voor het model van de veldjas" niet tegenVoor zover ik kan beoordelen is het Actorenregister niet volledig of wordt het niet meer actief bijgewerkt. Ook zie ik geen links vanuit de toegangen op de Nationaal Archief website naar het Actorenregister. Een gemiste kans lijkt me, een werkproces: "Actor checken en indien nodig aanmaken > Toegang maken (inclusief link naar Actor) > Toegang publiceren" zou volgens mij beide 'onvolkomenheden' kunnen ondervangen., maar natuurlijk wel het "Ministerie van Defensie" waar het onderdeel van was. Via het Actorenregister kan een EAC-CPF XML bestand van deze 'hoofd' Actor worden gedownload en als we dat in de RiC Editor hebben ingelezen levert dat 70 extra Actoren op, allemaal aan elkaar gerelateerd en herkenbaar aan hun geïmporteerde (Handle) identifier.
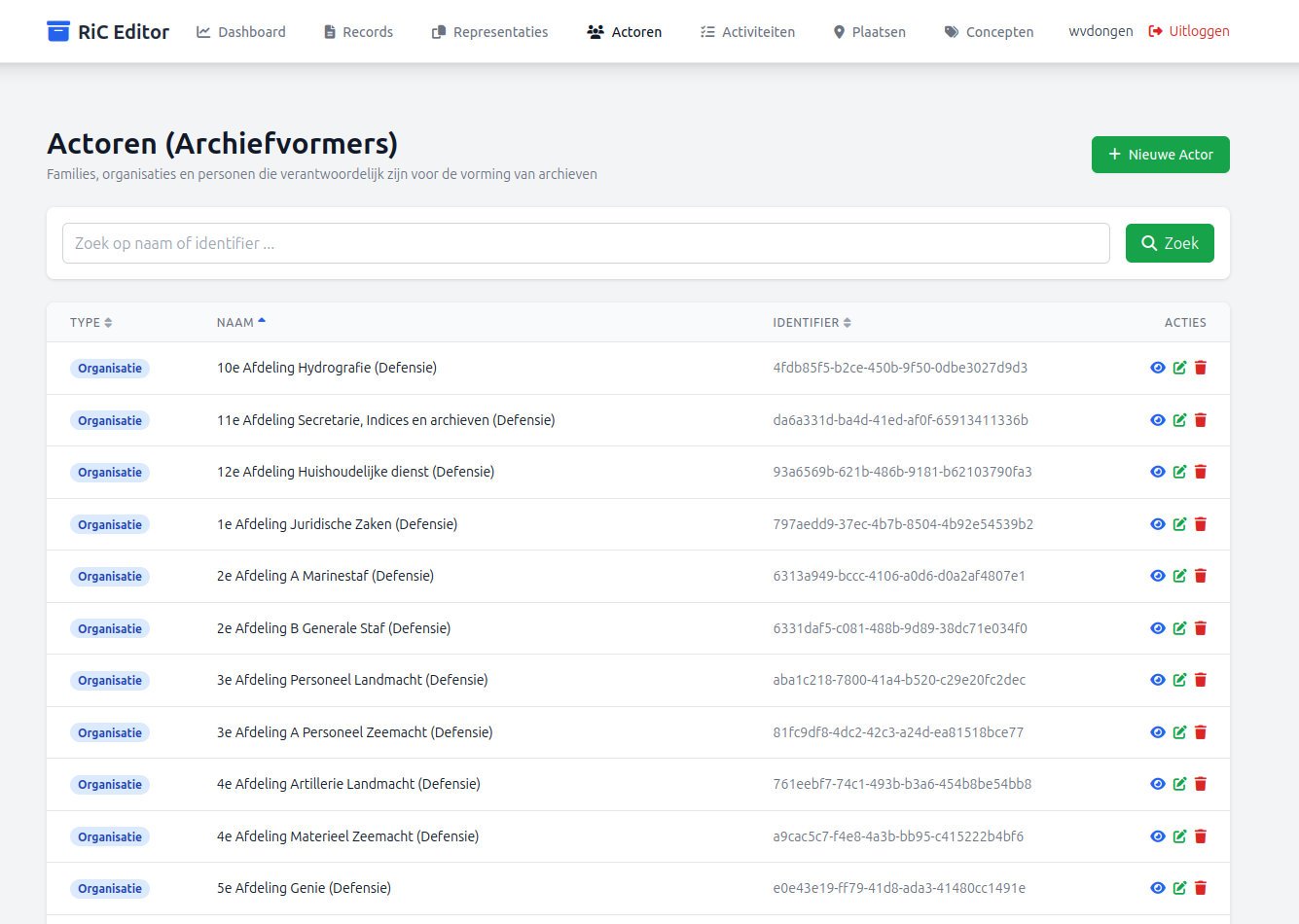
Als we in de RiC Editor zoeken binnen de aanwezige Actoren op: "Commissie" komt de "Commissie voor het model van de veldjas" ook in beeld en zien we het verschil: de Actoren afkomstig uit het Actorenregister hebben hun eigen (Handle) identifier en de uit toegang 2.13.80 geïmporteerde "Commissie voor het model van de veldjas" heeft een door de RiC Editor gegenereerde identifier, want die had er geen binnen: "/ead/archdesc/did/origination"Natuurlijk zou ik de RiC Editor hebben kunnen instrueren om deze Actor een identifier met daarin een verwijzing naar "2.13.80" mee te geven, maar dat zou iets te specifiek zijn en problemen opleveren bij import van een andere toegang met dezelfde Actor..
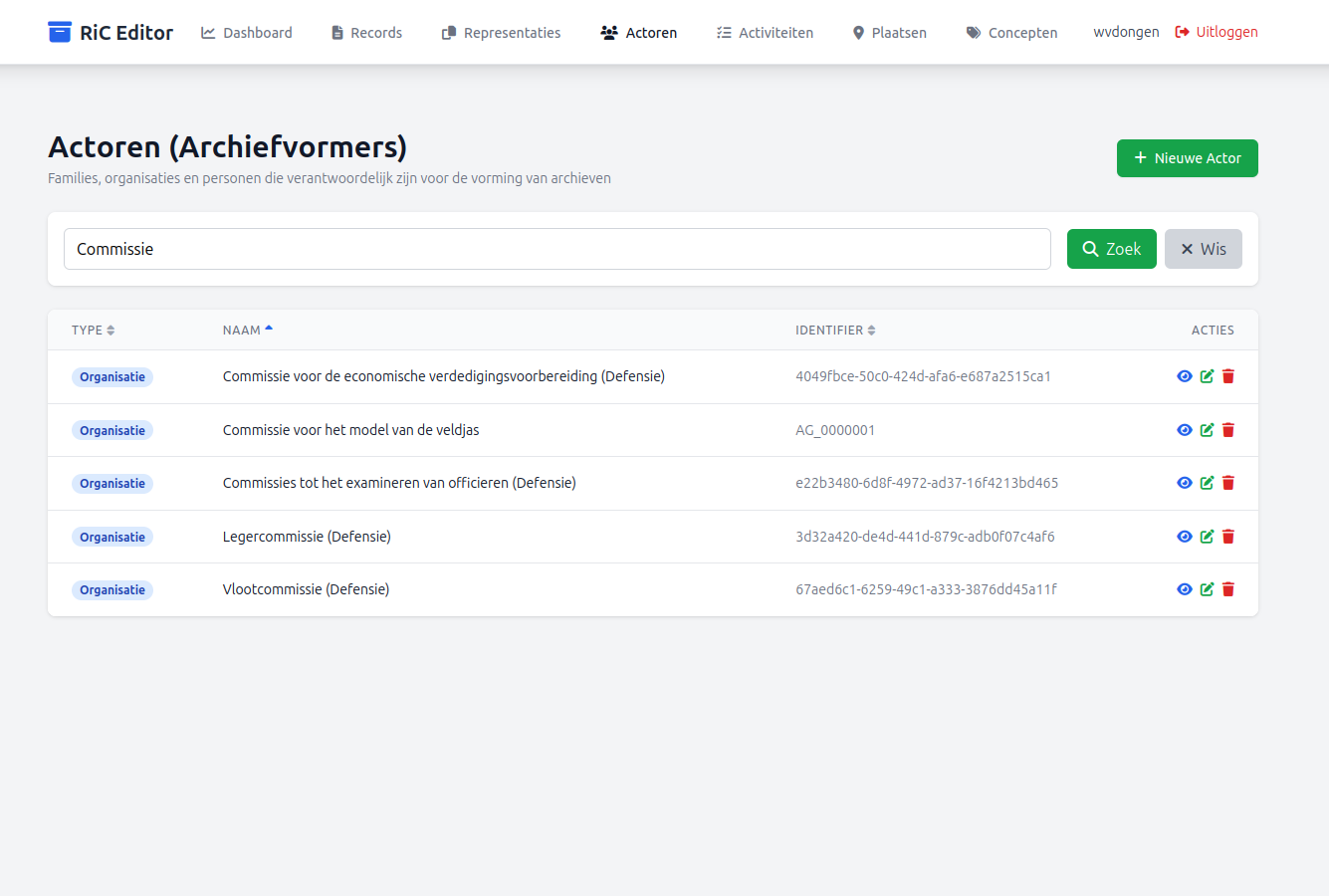
Nu kunnen we in de RiC Editor een relatie leggen tussen de Actor "Commissie voor het model van de veldjas" en de Actor "Ministerie van Defensie" en wel via de knop "Relatie toevoegen" in de detail pagina van een van deze Actoren, en het onderstaande screenshot laat dat zien vanuit de Actor "Commissie voor het model van de veldjas". In het dialoogscherm dat volgt op een klik op de knop "Relatie toevoegen" kunnen we een keuze maken uit de aard van de relatie en kunnen we de Actor selecteren waarmee die relatie gelegd moet worden.
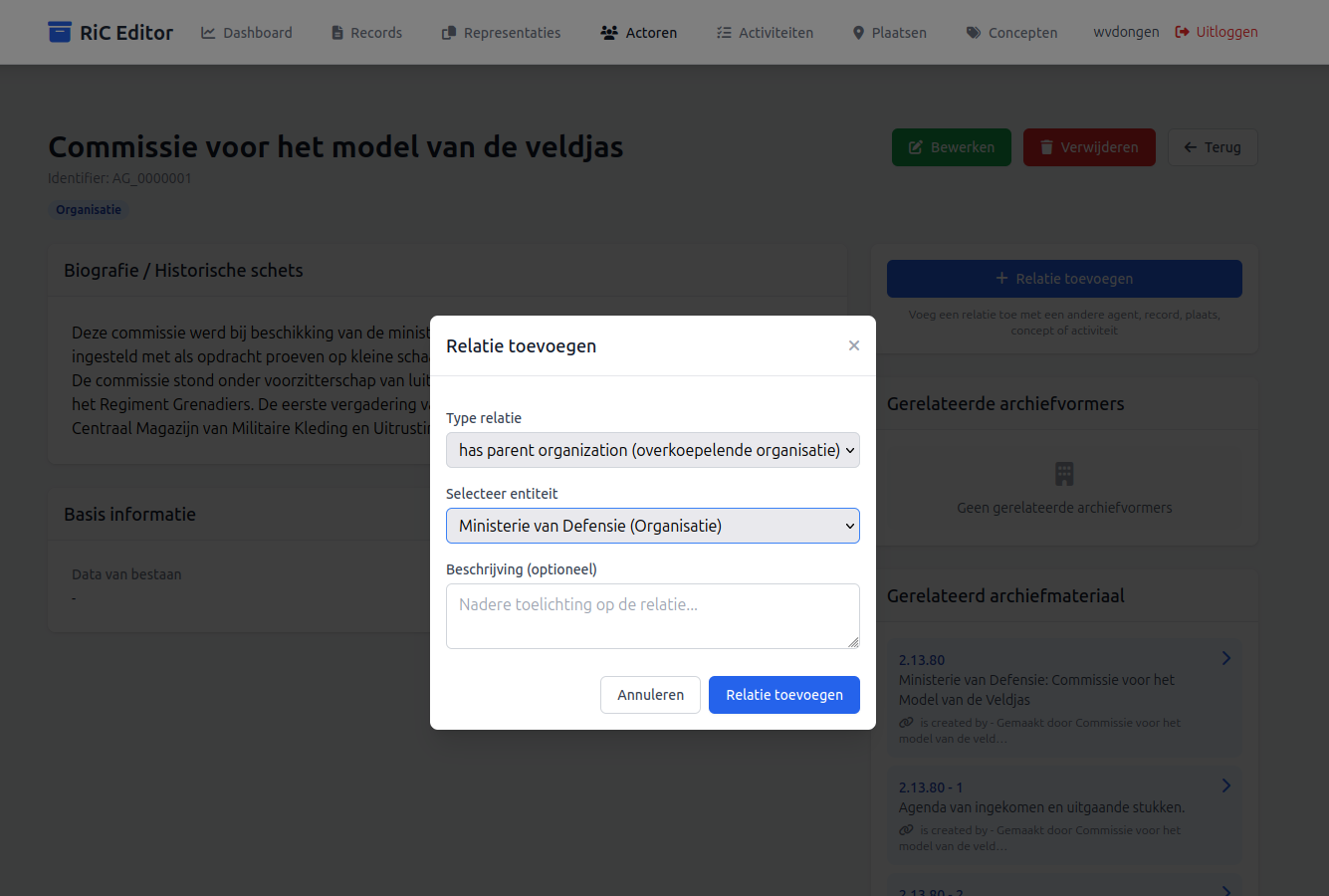
Na een klik op de knop "Relatie toevoegen" in het dialoogscherm wordt de detail pagina van de gekozen Actor weer getoond, met daarin onder "Gerelateerde acrhiefvormers" de zojuist aangemaakte relatie.
Als we nu vanuit het RiC Editor dashboard de RiC Relatie visualisatie opstarten en zoeken op bijvoorbeeld "veldjas", dan zien we een visualisatie van de inmiddels in de RiC Editor aanwezige relaties rond dit item: die van de "veldjas" Actor (inclusief zijn nieuw gerelateerde 'hoofd' Actor) en zijn gerelateerde Records.
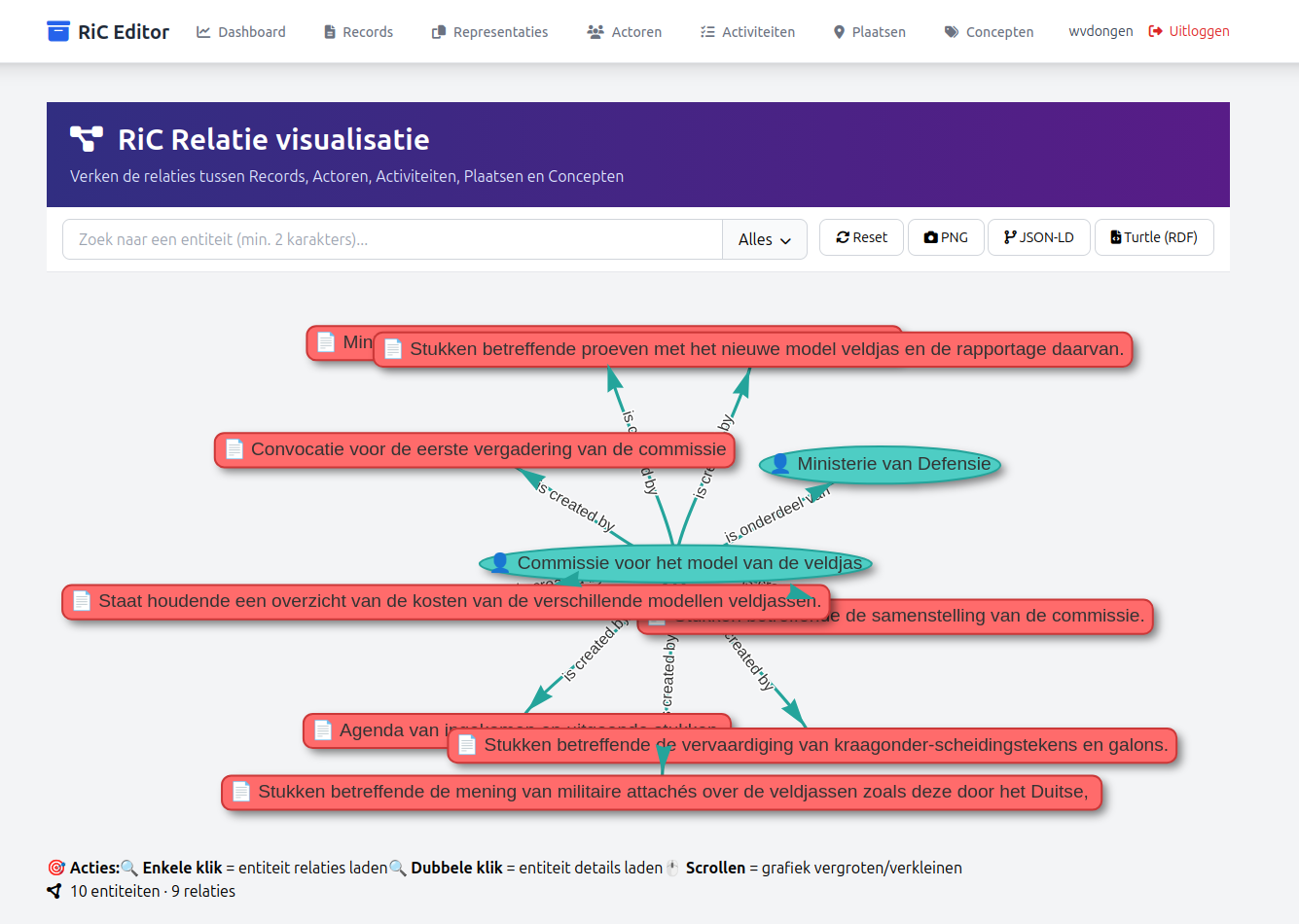
Zoals de legenda onder het visualisatie overzicht laat zien, kan van hieruit worden gekozen voor de visualisatie van de relaties van een andere entiteit (via één klik op die andere entiteit in het visualisatie scherm) of voor de weergave van de detail pagina van een van de getoonde entiteiten (via een dubbele kik op de betreffende entiteit in het visualisatie scherm). Veder laat de menu balk zien dat er een export van de visualisatie kan worden gemaakt, en wel als een afbeelding (PNG) of een JSON-LD of RDF Turtle bestand, voor gebruik elders.
Het vervolg
Inmiddels staat op mijn laptop (en op mijn shared webhosting omgevingWil je er hier al mee 'spelen', voel je vrij mij een bericht te sturen.) een eerste werkende versie van de RiC Editor. Nog verre van compleet, ongetwijfeld hier en daar semantisch discutabel, en waarschijnlijk zullen RiC-puristen over meerdere keuzes hun wenkbrauwen optrekken. Maar eerlijk gezegd was en is het voor mij een interessante exercitie. Want tijdens het bouwen werd me steeds duidelijker dat RiC niet simpelweg een nieuwe beschrijvingsstandaard is, maar vooral een andere manier van kijken naar archiefinformatie. Niet het document staat centraal, maar het netwerk waarin dat document betekenis krijgt. En precies daarom denk ik dat goede tooling uiteindelijk cruciaal zal zijn voor bredere adoptie van RiC. Niet door alle theoretische rijkdom van het model meteen beschikbaar te maken, maar juist door die complexiteit hanteerbaar te maken voor iedereen die archieven beschrijft, beheert en toegankelijk maakt.
Binnenkort zal ik de code van deze eerste versie van de RiC Editor als open source software project publiceren. Waarschijnlijk via GitHub of - vanwege de discussie rondom onze digitale afhankelijkheid van de inmiddels beruchte "TechBros" - misschien toch via Codeberg, daar ben ik eerlijk gezegd nog niet helemaal uit. Maar dat is weer een heel ander verhaal in een heel andere context.